
七步为基于图像的AI项目准备数据集

译者 | 陈峻
审校 | 重楼
不知你是否注意到,数据集可能是机器学习项目中最容易被忽视的部分。在大多数人看来,数据集不过是一些快速拼凑、或已下载的预制图像的集合。而实际上,数据集是任何基于图像的人工智能(AI)项目的基石。对于任何旨在实现高准确性的机器学习项目来说,创建和管理一个平衡且结构合理的数据集,都是至关重要的。
不过,创建一个数据集并不像收集几百张图片那么简单。我们在尝试启动某个AI项目时,很可能会遇到各种隐患。下面,我将和您讨论可用来创建自己的数据集的七个典型步骤,以便您深入了解数据集大小的重要性、可能出现的数据遗漏、以及将数据集转化为数据库等要素。
注意:这些步骤将主要适用于,那些针对包含了图像数据集的对象检测和分类项目。而诸如 NLP 或图形项目等其他项目类型,则需要采用不同的方法。
步骤 1:图像大小
通常,神经网络仅能处理特定的图像大小,而任何超过阈值的图像都会被强制缩小。也就是说,在使用数据集之前,我们需要选择合适的神经网络,并对图像大小做相应的调整。
如您所知,图像尺寸的缩小可能会导致精确度大幅下降,让图片上小的物体消失,进而对整个识别过程造成损害。如下图所示,您需要在监控摄像头所拍摄到的图像上检测出汽车牌号码。而车牌只占有整个图像的一小部分。那么当神经网络对图像进行缩小处理时,车牌号就可能因为变得非常小,而无法被识别到。
如下图所示,如果能够了解网络可使用的图像尺寸,将有助于您裁剪出适当的数据集图像。

虽然大多数神经网络可处理的图像尺寸都比较小,但是诸如 Yolo v5x6之类的最新神经网络,则能够处理更大分辨率的图像。例如,Yolo v5xs6就能够处理宽达 1280 像素的图像。
步骤 2:了解您的环境
为了让数据集能够反映神经网络在运行过程中待识别的真实图像,我们在收集数据集时,需要注意如下因素:
- 摄像头的类型,是智能手机摄像头,还是安全摄像头
- 图像的大小
- 摄像头的位置,是在室内,还是室外
- 天气条件,如光照、雨、雾、雪等。
在清楚了解了神经网络待处理的真实图像后,我们就能够创建一个数据集,来准确地反映那些感兴趣的对象、及其所处的环境。
您可能会直观地认为收集谷歌上的普通图片,可能是组建大型数据集的最简单、最快捷的方法。但是由此所产生的系统,实际上很难达到较高的精确度要求。如下图所示,与真实相机所拍摄的图像相比,谷歌或照片数据库中的图像通常是被“美颜”过的。

而一个过于“漂亮”的数据集,很可能会导致较高的测试准确率。这意味着,神经网络将仅能在测试数据(从数据集中提纯过的图像集合)上良好运行,但在真实条件下运行不佳,并导致准确率低下。
步骤 3:格式和注释
我们需要注意的另一个重要方面是:图片的格式。在开始项目之前,请检查您选择的框架能够支持哪些格式,而您的图片是否能够符合此类要求。虽然当前的框架已能够支持多种图片格式,但是对于 .jfif等格式仍存在问题。
注释数据可以被用来详细地说明边界框、文件名、以及可以采用的不同结构。通常,不同的神经网络和框架,需要不同的注释方法。有些需要包含边界框位置的绝对坐标,有些则需要相对坐标;有些要求每幅图像都附带有一个单独的、包含了注释的.txt 文件,而另一些仅需要一个包含了所有注释的文件。可见,即使您的数据集拥有良好的图像,如果您的框架无法处理注释的话,也将无济于事。
步骤 4:训练和验证子集
出于训练目的,数据集通常被分成两个子集:
- 训练子集- 它是一组图像。神经网络将会在这组图像上进行训练。其占比为图像总数的 70% 至 80%。
- 验证子集- 是用于检查神经网络在训练过程中学习效果的较小图像集。其占比为图像总数的 20% 到 30% 之间。

通常,神经网络会使用从训练子集中提取到的物体特征,来“学习”物体的外观。也就是说,在一个训练周期结束(历时,epoch)后,神经网络会查看验证子集的数据,并尝试猜测它能够 “看 ”到那些物体。无论是正确的、还是错误的猜测,其结构都能够让神经网络进一步去深入学习。
虽然这种方法已被广泛使用,并被证明能够取得良好的效果,但我们更倾向于采用一种不同的方法,将数据集划分为如下子集:
- 训练子集 - 占图像总数的 70%
- 验证子集 - 占图像总数的 20%
- 测试数据集 - 约占图像总数的10%

由于测试子集包含了神经网络从未见过的数据集中的图像,因此开发人员可以通过该子集来测试模型,以了解其手动运行的效果,以及在处理哪些图像时会遇到困难。换句话说,该子集将有助于在项目启动前,找出神经网络可能犯错的地方,进而避免在项目启动之后,进行过多的重新训练。
步骤 5:数据遗漏
如果您用来训练机器学习算法的数据中,恰好包含了您试图预测的信息,那么就可能发生数据泄露。如下图所示,从图像识别的角度来看,当训练子集和验证子集中的同一对象的照片非常相似时,就会发生数据泄露。显然,数据遗漏对于神经网络的质量来说是极为不利的。

从本质上说,模型在训练数据集中看到了一幅图像后,会先提取其特征,然后进入验证数据集,进而发现看到的完全相同(或非常相似)的图像。因此,与其说模型在真实学习,不如说它只是在记忆各种信息。有时,这会导致验证数据集上的准确率,高得离谱(例如,可高达 98%),但是在生产实际中的准确率却非常低。
目前最常用的一种数据集分割方法是:将数据随机打乱,然后选取前 70% 的图像放入训练子集,剩下的 30% 则放入验证子集。这种方法就容易导致数据遗漏的产生。如下图所示,我们的当务之急是从数据集中删除所有“重复”的照片,并检查两个子集中是否存在相似的照片。

对此,我们可以使用简单的脚本来自动执行重复删除。当然,您可以调整重复阈值,比如:只删除完全重复的图片、或相似度高达到 90% 的图片等。总的说来,只要删除的重复内容越多,神经网络的生产精度就会越高。
步骤 6:大型数据集数据库
如果您的数据集相当大,例如:超过 10万 幅图像、以及具有几十个对象类与子类的话,我们建议您创建一个简单的数据库,来存储数据集信息。这背后的原因其实非常简单:对于大型数据集而言,我们很难跟踪所有的数据。因此,如果不对数据进行某种结构化的处理,我们将无法对其进行准确分析。
通过数据库,您可以快速地诊断数据集,进而发现诸如:特定类别的图片数量过少,会导致神经网络难以识别出对象;类别之间的图片分布不够均匀;特定类别中的谷歌图片数量过多,导致该类别的准确率得分过低等情况。
通过简单的数据库,我们可以包含如下信息:
- 文件名
- 文件路径
- 注释数据
- 类数据
- 数据源(源自生产环境、还是谷歌等)
- 对象类型、名称等对象相关信息
可以说,数据库是收集数据集统计数据不可或缺的工具。它可以协助我们快速、轻松地查看到数据集的平衡程度,以及每个类别中有多少高质量(从神经网络的角度来看)的图像。根据类似如下直观呈现出来的数据,我们可以更快地进行分析,并将其与识别的结果进行比较,从而找出准确率低下的根本原因。
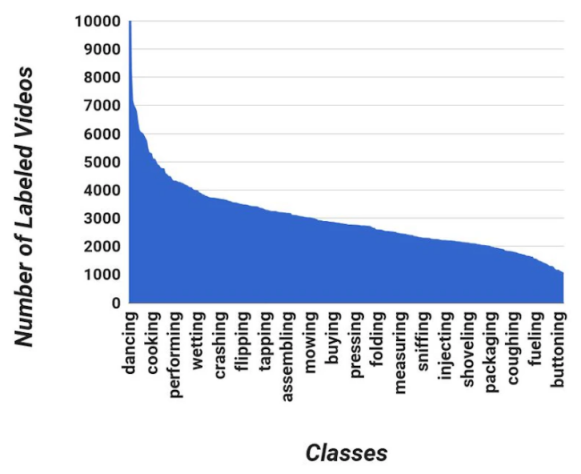
值得注意的是,准确率低下的一个原因,可能源于图片数量较少、或某一类中谷歌照片的比例较高。而通过创建此类数据库,则可以大幅减少生产、测试、以及模型再训练的时间。
步骤 7:数据集增强
作为一种用于增加图像数量的技术,数据增强是对数据进行简单或复杂转换的过程,例如通过翻转或样式转化,我们可以提高数据的有效性。而据此获得的有效数据集,则无需经历过多的训练。如下图所示,此类数据转换既可以是简单到仅将图像旋转 90 度,也可以复杂到在图像中添加太阳耀斑、以模仿背光照片或镜头耀斑。

通常,此类增强转化都是自动执行的。例如,我们可以准备一个专门用于数据增强的 Python 库。目前,数据增强有两种类型:
- 训练前增强- 在训练过程开始之前,对数据进行扩增,并将其添加到训练子集中。当然,只有在数据集被划分为训练子集和验证子集之后,我们才能进行此类增加,以避免出现前文提到的数据遗漏。
- 训练内增强- 采用类似 PyTorch的框架内置图像变换技术。
值得注意的是,将数据集的大小增加十倍,并不会使得神经网络的效率提高十倍。事实上,这反而可能会使网络的性能比以前更差。因此,我们应当只使用与生产环境相关的增强功能。例如,对于被安装在建筑物内的摄像机,在其正常运行的情况下,是不会出现雨淋的。因此我们完全没有必要在图像中添加针对“雨景”的增强。
小结
尽管对于那些希望将AI应用到业务中的人们来说,数据集是最不令人兴奋的部分。但不可否认的是,数据集是任何图像识别项目中的重要部分。而且在大多数图像识别项目中,数据集的管理和整理,往往会花费团队大量的时间。最后,让我们小结一下,该如何通过恰当地处置数据集,以便从AI项目中获得最佳结果:
- 裁剪或调整图像的大小,以满足神经网络的要求
- 根据天气和照明条件,采集真实图像
- 根据神经网络的要求,构建注释
- 避免使用所有的图像来训练网络。而需留一部分用于测试
- 删除验证数据集中的重复图像,以避免数据遗漏
- 创建数据库,以快速诊断数据集
- 尽量少用数据增强,来增加图像数量
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:7 Steps To Prepare A Dataset For An Image-Based AI Project,作者:Oleg Kokorin