
押注核能!微软决心喂大模型新“弹药”!
撰稿 | 云昭
微软雄心勃勃,在Windows11全面AI化的同一天,再被曝出新动作。
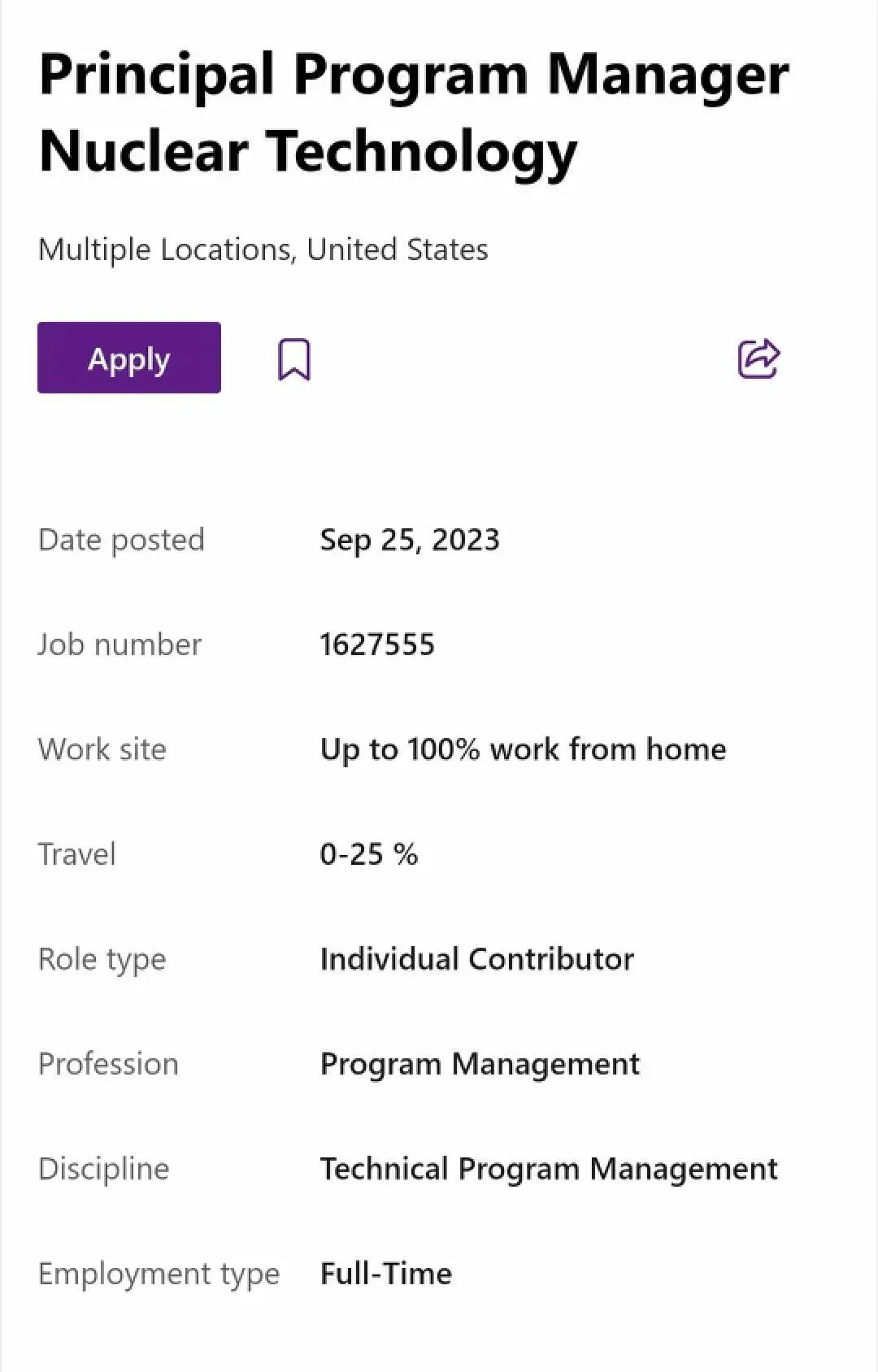
当地时间9月25日,微软在官网上突然挂出了一则“核技术首席项目经理”的招聘消息。不难看出,继微软云之后,纳德拉在对待大模型这件事情,可谓火力全开。
但令人意外的是,从“Office全家桶”接入GPT4、Azure提供云资源,再到最近的Windows11全面AI化,就在全新的微软呼之欲出的时候,为什么微软竟决定对能源这块也要下手呢?
1、人工智能和和核能,微软一个都不放过!
微软正在招募的“核技术首席项目经理”岗位,任务是领导全球小型模块化反应堆( Small Modular Reactor, SMR)和微反应器集成的技术评估,为微软云和 AI所在的数据中心提供动力。“这一岗位将为技术集成保持清晰且适应性强的路线图,认真选择和管理技术合作伙伴和解决方案,并不断评估进展和实施的业务影响。”招聘帖子中如是说。
图源:微软
此外,微软对于这一岗位的理想候选人也给出了要求:应具有能源行业的经验,并对核技术和监管事务有深入的了解。该职位还将负责研究和开发其他商业化前的能源技术。
2、大模型“跑废”特斯拉!
知名业内专家吴军,曾对ChatGPT训练有一个比喻:每训练一次ChatGPT,相当于让3000辆特斯拉电动汽车在一个月走完了21年的路,基本全跑废掉。这一形容并不夸张。
根据斯坦福人工智能研究所(HAI)发布的《2023年人工智能指数报告》,训练GPT3所需的电量,足够让一个普通美国家庭用上数百年。而据国盛证券估算,GPT-3的单次训练成本就高达140万美元,对于一些更大的LLM(大型语言模型),训练成本介于200万美元至1200万美元之间。
 数据来源:Luccioni et al.
数据来源:Luccioni et al.
“大模型训练成本中60%是电费,”华为AI首席科学家田奇也曾对电力问题表示担忧,认为电力的降本增效已迫在眉睫。如果大模型普及,全球飞速运转的服务器,怕不会把地球烧了。
也无怪乎,OpenAI创始人周一在一场活动上表示现在对于GPT而言,重点在于“降低成本和提高可靠性”,而不是急于推出GPT-5。
3、为了省电,硅谷大佬们思路大开
首先看微软。目前看,微软将目光锁定在了核能。大家可能不知道,比尔·盖茨还有另外一个身份,就是核创新公司TerraPower的董事长,该公司正在开发和推广小型模块化反应堆设计。不过,TerraPower的一位发言人称,“目前没有任何向微软出售反应堆的协议。”
美国能源情报署的数据显示,美国现有的核反应堆目前的发电量约占美国总发电量的18%。而下一代核反应堆技术的希望很大程度上寄托在小型核反应堆上。
顾名思义,小型核反应堆比传统反应堆更小,建造起来也更便宜、建设速度更快,因为它们采用模块化结构设计,并不是反应堆的每个部件都需要定制。
此外,微软方面已经公开承诺将从核聚变领域创新者那里寻求核能。今年5月,微软宣布与核聚变初创公司Helion签署了一项电力购买协议,将于2028年从Helion购买电力。碰巧的是,OpenAI首席执行官萨姆·奥特曼,也是Helion的早期重要投资者。
还有,大名鼎鼎的“硅谷钢铁侠”马斯克对于能源这块也有过考虑。4月就有传闻,马斯克和贝索斯准备联手训练一个超级大模型。为了节约制冷和耗能,两位竟然提出了一个“太空数据中心”的计划,把五万片H100英伟达卡由SpaceX送到太空,并携带巨量的太阳能板,以期借由太空的力量解决电力的问题。不过有专家分析这个方案不靠谱,目前卫星太阳能帆板的供电系统普遍功率只有1200W,无论是电力供应还是成本,都不如地面的解决方案。
 图片
图片
当然,还有一种比较靠谱的方案,就是优化芯片本身的耗能。这种能耗管理的逻辑是,数据中心有多块芯片,每个芯片上有几十亿甚至上百亿的晶体管,一个晶体管,相当于一个用电单位,以此推断,一颗指甲盖大小的芯片,就是一个规模庞大的能源网络。如果能够将每个晶体管的能耗优化,那么最后的节能就能辐射到整个数据中心。
这块探索比较多的是全球EDA龙头企业新思科技,早在7年前就启动了一项叫做“高能效设计”的项目,将芯片的能效最大化。
4、微软,仅仅是想解决能耗问题?
微软此举,不止是出于对AI的押注和数据中心动力来源的考虑,还有着其他的原因。
据外媒theVerge称,比尔盖茨一直以来都是核能的忠实粉丝,因为核能不会产生温室气体的排放,对于应对气候变化方面或发挥着一定的作用。
此外,有关大模型能源消耗问题,其实并没有想象的那么严峻。一位资深分析师人士坦言,市场大可不必对大模型的能耗问题过度担忧。“很多人忽略了一个事实,那就是大模型对算力的需求未来必然会逐渐下降,这意味着能耗也会相应降低。”
比如,微软在4月12日开源的DeepSpeed-Chat就充分说明了这一点,它可将训练速度提升15 倍以上,算力成本大大降低。仅凭单个 GPU就能支持一个130亿参数的类ChatGPT模型,训练时间也只需要 1.25 小时。
最后,只能说,变革的齿轮一旦启动,就很难逆转。微软此番对于AI的投入超乎了业界对它的想象。
参考链接:
https://www.theverge.com/2023/9/26/23889956/microsoft-next-generation-nuclear-energy-smr-job-hiring
https://www.bilibili.com/read/cv23092171/
https://baijiahao.baidu.com/s?id=1778038558952820880