
让知识图谱成为大模型的伴侣
大型语言模型(LLM)能够在短时间内生成非常流畅和连贯的文本,为人工智能的对话、创造性写作和其他广泛的应用开辟了新的可能性,然而,LLM也有着一些关键的局限性。它们的知识仅限于从训练数据中识别出的模式,这意味着缺乏对世界的真正理解。同时,推理能力也是有限的,不能进行逻辑推理或从多种数据源来融合事实。面对更复杂、更开放的问题时,回答开始变得荒谬或矛盾,美其名曰“幻觉”。
为了弥补这些差距,检索增强生成(RAG)系统开始涌现,其核心思想是从外部来源检索相关知识,为 LLM 提供上下文,以便作出更明智的反应。现有的系统大多使用向量嵌入的语义相似度来检索段落。然而,这种方法有它自己的缺点,如缺乏真正的相关性,无法聚合事实,也没有推理链。这正是知识图谱的应用领域。知识图谱是..现实世界实体和关系的结构化表达。它们通过编码上下文事实之间的相互联系,克服了纯向量搜索的缺陷,通过图搜索可以跨多种信息源进行复杂的多级推理。
向量嵌入和知识图谱的结合可以开启更高水平的推理能力,进而提升LLM的准确性和可解释性。这种伙伴关系提供了表层语义以及结构化知识和逻辑的完美融合,LLM 既需要统计学习,也需要符号表示。
图片
1. 向量搜索的局限
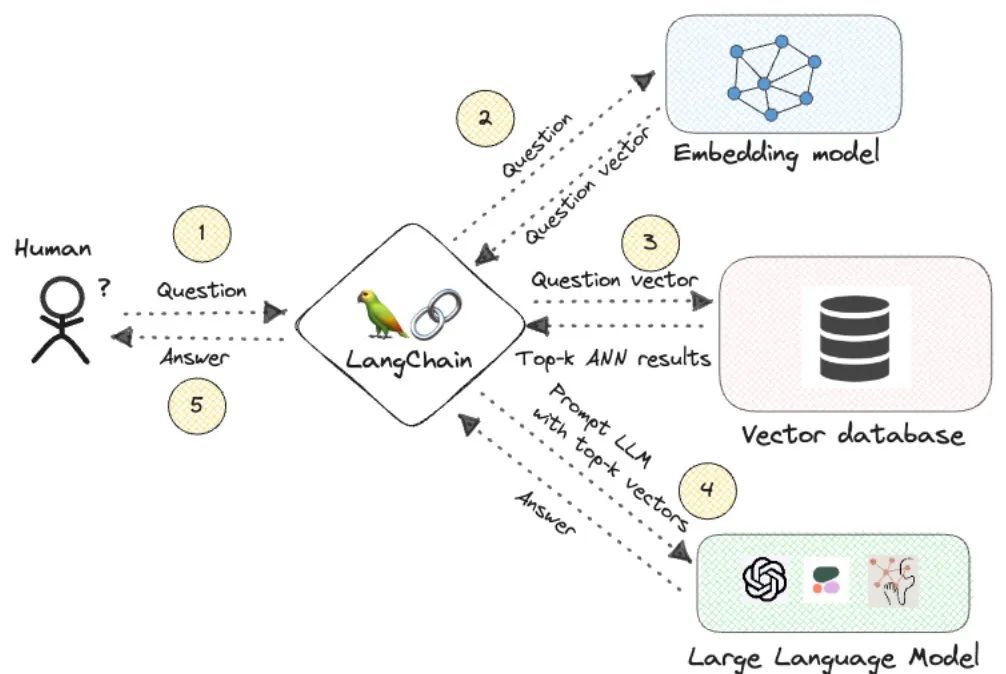
大多数 RAG 系统依赖于通过文档集合中段落的向量搜索过程来查找 LLM 的相关上下文。这一过程有几个关键步骤:
- 文本编码: 系统使用像 BERT 这样的嵌入模型将文本从语料库中的段落编码成向量表示。每篇文章都被压缩成一个密集的向量来捕捉语义。
- 索引: 这些通道向量在高维向量空间中进行索引,以实现快速的最近邻搜索。流行的方法包括 Faiss 和 Pinecone等。
- 查询编码: 用户的查询语句也被编码为使用相同嵌入模型的向量表示。
- 相似性检索: 一个最近邻搜索在索引的段落中运行,根据距离指标(如余弦距离)找到与查询向量最接近的段落。
- 返回段落结果: 返回最相似的段落向量,提取原始文本为 LLM 提供上下文。
这种流水线有几个主要的局限性:
- 通道向量可能无法完全捕获查询的语义意图,嵌入不能表示某些推理连接,重要的上下文最终会被忽视。
- 把整个段落压缩成单个向量会丢失细微差别,嵌入在句子中的关键相关细节会变得模糊。
- 匹配是为每个段落独立完成的,没有跨越不同段落的联合分析,缺乏连接事实和得出需要汇总的答案。
- 排名和匹配过程是不透明的,没有透明度来解释为什么某些段落被认为更相关。
- 只有语义相似性被编码,没有表示关系,结构,规则和其他不同的连接之间的内容。
- 对语义向量相似性的单一关注导致检索缺乏真正的理解。
随着查询变得越来越复杂,这些限制在无法对检索到的内容进行推理方面变得越来越明显。
2. 整合知识图谱
知识图谱表示实体和关系在相互连接的网络中的信息,能够实现跨内容的复杂推理,进而增强检索的能力:
- 显式的事实,事实直接作为节点和边捕获,而不是压缩成不透明的向量,这保留了关键的细节。
- 上下文细节,实体包含了丰富的属性,如提供关键上下文的描述、别名和元数据等。
- 网络结构表达了关系建模实体之间的真实连接、捕获规则、层次结构、时间线等。
- 多级推理基于关系遍历以及连接来自不同来源的事实,可以推导出需要跨多个步骤进行推理的答案。
- 联合推理通过实体解析链接到同一个现实世界的对象,从而允许进行集体分析。
- 可解释的相关性,图形拓扑提供了一种透明度,可以解释为什么某些基于连接的事实是相关的。
- 个性化,捕获用户属性、上下文和历史交互以定制结果。
知识图谱不是孤立的匹配,而是通过图遍历的过程能够收集与查询相关的相互关联的上下文事实。可解释的ranking基于图的拓扑结构,通过编码结构化事实、关系和上下文来增强检索能力,从而实现精确的多步推理。与纯向量搜索相比,这提供了更大的相关性和解释能力。
3. 利用简单约束改进知识图谱的嵌入
在连续向量空间中嵌入知识图谱是当前的研究热点。知识图谱可以将实体和关系表示为向量嵌入,以支持数学运算,额外的约束可以使表示更加优化,例如:
- 非负性约束,将实体嵌入限制为0到1之间的正值会导致稀疏性,明确地模拟了它们的正性质,并提高了可解释性。
- 蕴涵约束,将对称、反转、合成等逻辑规则直接编码为关系嵌入的约束来强制这些模式。
- 置信度建模,带松弛变量的软约束可以根据证据对逻辑规则的置信度进行编码。
- 正则化,施加了有用的归纳偏差,只增加了一个投影步骤,而没有使优化变得更加复杂。
- 可解释性,结构化约束为模型所学习的模式提供了透明度,这解释了推理过程。
- 精确性,约束通过将假设空间减少到符合要求的表示方法来提高泛化能力。
简单通用的约束增加到知识图谱的嵌入,从而产生更优化、更易于解释和逻辑兼容的表示。嵌入获得模仿真实世界结构和规则的归纳偏差,这对更准确和可解释的推理并没有引入太多额外的复杂性。
4. 集成多种推理框架
知识图谱需要推理来得出新的事实,回答问题,并做出预测,不同的技术有着互补的优势:
逻辑规则将知识表述为逻辑公理和本体,通过定理证明进行合理和完整的推理,实现有限的不确定性处理。而图嵌入用于向量空间运算的嵌入式知识图结构,能处理不确定性但缺乏表达性。神经网络结合向量查找具有自适应性,但推理不透明。通过对图结构和数据的统计分析能够自动创建规则,但质量不确定。混合流水线通过逻辑规则进行编码明确的约束,嵌入提供向量空间操作,神经网络通过联合训练获得融合的收益。使用基于案例、模糊或概率逻辑的方法来增加透明度,表达不确定性和对规则的置信度。通过将推断的事实和学到的规则具体化到图谱中来扩展知识,提供反馈循环。
关键是确定所需的推理类型,并将它们映射到适当的技术,结合逻辑形式、向量表示和神经元组件的可组合流水线提供了健壮性和可解释性。
4.1 保持 LLM 的信息流
为 LLM 检索知识图谱中的事实会引入信息瓶颈,需要通过设计保持相关性。将内容分成小块可以提高隔离性,但会失去周围的上下文,这会阻碍分块之间的推理。生成块的摘要可以提供更简洁的上下文,关键细节被压缩以突出显示意义。将附加摘要、标题、标记等作为元数据,以维护有关源内容的上下文。将原始查询重写为更详细的版本,可以更好地针对 LLM 的需求进行检索。知识图谱的遍历功能保持了事实之间的联系,维护上下文。按时间顺序或按相关性排序可以优化 LLM 的信息结构,将隐式知识转换为为 LLM 所陈述的显式事实可以使推理变得更容易。
目标是优化检索知识的相关性、上下文、结构和显性表达,以最大限度地提高推理能力。需要在粒度和内聚性之间取得平衡。知识图关系有助于为孤立的事实构建上下文。
4.2 解锁推理能力
知识图表和嵌入式技术结合起来都有克服对方弱点的优势。
知识图谱提供了实体和关系的结构化表达。通过遍历功能来增强复杂推理能力,处理多级推理;嵌入是在向量空间中为基于相似性的操作编码信息,支持在一定尺度上进行有效的近似搜索,将潜在模式表面化。联合编码为知识图谱中的实体和关系生成嵌入。图神经网络通过可微消息传递对图结构和嵌入元素进行操作。
知识图谱首先收集结构化知识,然后嵌入聚焦于相关内容的搜索和检索,外显知识图关系为推理过程提供了可解释性。推断知识可以扩展为图谱,GNN 提供了连续表示的学习。
这种伙伴关系可以通过模式识别!力和神经网络的可扩展性增强了结构化知识的表示。这是推进语言人工智能需要统计学习和符号逻辑的关键。
4.3 用协同过滤改进搜索
协同过滤利用实体之间的联系来加强搜索,一般过程如下:
- 构造一个节点表示实体和以边表示关系的知识图谱。
- 为某些关键节点属性(如标题、描述等)生成一个嵌入向量。
- 向量索引ーー构建节点嵌入的向量相似度索引。
- 最近邻搜索ーー对于搜索查询,查找具有大多数相似嵌入的节点。
- 协作调整ーー基于节点的连接,使用 PageRank 等算法传播和调整相似性得分。
- 边缘权重ー根据边缘类型、强度、置信度等进行权重调整。
- 分数标准化ーー将调整后的分数标准化以保持相对排名。
- 结果重新排序ーー基于调整后协作分数的初始结果重新排序。
- 用户上下文ーー进一步根据用户配置文件、历史记录和首选项进行调整。
 图片
图片
5. 为 RAG 引擎加油——数据飞轮
构建一个不断改进的高性能检索增强生成(RAG)系统可能需要实现数据飞轮。知识图谱通过提供结构化的世界知识为语言模型开启了新的推理能力。但是,构建高质量的图谱仍然具有挑战性。这就是数据飞轮的用武之地,通过分析系统交互,不断改进知识图。
记录所有系统查询、响应、分数、用户操作等数据,提供如何使用知识图表的可视性,使用数据聚合到表面不良响应,聚类并分析这些响应,以识别表明知识差距的模式。人工回顾那些有问题的系统响应,并将问题追溯到图谱中缺少的或不正确的事实。然后,直接修改图表以添加那些缺失的事实数据、改进结构、提高清晰度等。不断循环完成上述步骤,每次迭代都进一步增强知识图。
像新闻和社交媒体这样的流媒体实时数据源提供了新信息的不断流动,以保持知识图表的最新性。如果使用查询生成来识别和填补关键的知识空白,就超出了流提供的范围。发现图谱中的漏洞,提出问题,检索缺失的事实,然后添加它们。对于每个循环,通过分析使用模式和修复数据问题,知识图谱会逐渐增强,改进后的图增强了系统的性能。
这个飞轮过程使得知识图谱和语言模型能够基于来自现实世界使用的反馈进行协同演化。图谱被积极地修改以适应模型的需要。
总之,数据飞轮通过分析系统交互,为知识图谱的持续、自动改进提供了一个支架。这为依赖于图表的语言模型的准确性、相关性和适应性提供了动力。
6. 小结
人工智能需要结合外部知识和推理,这就是知识图谱的用武之地。知识图谱提供了真实世界实体和关系的结构化表示,编码了关于世界的事实以及它们之间的联系。通过遍历那些相互关联的事实,这使得复杂的逻辑推理可以跨越多个步骤
然而,知识图谱有其自身的局限性,如稀疏性和缺乏不确定性处理,这就是图谱嵌入的帮助所在。通过在向量空间中编码知识图谱元素,嵌入允许从大型语料库到潜在模式表征化的统计学习,还支持高效的基于相似性的操作。
无论是知识图谱还是向量嵌入本身都不足以形成类人的语言智能,但是,它们共同提供了结构化知识表示、逻辑推理和统计学习的有效结合,而知识图谱覆盖了神经网络模式识别能力之上的符号逻辑和关系,像图神经网络这样的技术通过信息传递图结构和嵌入进一步统一了这些方法。这种共生关系使得系统既能利用统计学习,又能利用符号逻辑,结合了神经网络和结构化知识表示的优势。
在构建高质量的知识图谱、基准测试、噪音处理等仍然存在着挑战。但是,跨越符号和神经网络的混合技术仍然是前景光明的。随着知识图谱和语言模型的不断发展,它们的集成将开辟了可解释AI 的新领域。