
GPT-5史诗级更新之前,OpenAI的“新东西”来了,曝定价百万字符15美元,语音克隆引擎让老外说“有口音的”中文

撰稿 | 伊风
出品 | 51CTO技术栈(微信号:blog51cto)
OpenAI的新动作来了!此前Altman在采访中透露,在GPT-5史诗级的升级发布之前,OpenAI将在未来几个月发布许多“很酷的新东西”。
今天,OpenAI语音引擎首次亮相,效果的确惊艳!更重要的是它的合成效率之高——只需要用户上传任何 15 秒的语音样本,就能生成该语音的合成副本。
产品负责人哈里斯说,为语音引擎提供支持的生成式人工智能模型已经隐藏在人们的视线中一段时间了。OpenAI的新动作势必让语音克隆技术杀回我们的视野。
虽然算是突发新闻。但此次更新也是有端倪可循的。一周之前,X上的科技博主@Smoke-away 就发现OpenAI悄悄地注册了VOICE ENGINE商标。
图片
此前,网友也发现过OpenAI新的网站Feather(意为羽毛,详细新闻见链接),但这个神秘项目却迟迟没有下文。
不过这一次, OpenAI这次的动作确实够快的!
一、语音引擎要做什么?
OpenAI在其介绍页展示了几个令人印象深刻的案例。语音引擎的音色克隆效果自然、流畅,在不同语种之间切换时非常真实的保留了音色的特点,大家可以通过听合成的中文音频来更深地体会语音引擎的优秀(手动狗头)。
1.教育场景-帮助视觉受损者和儿童阅读
通过语音引擎的合成,能生成了比传统预设声音更为丰富和多样的声音,从而提升需要帮助者的阅读体验。
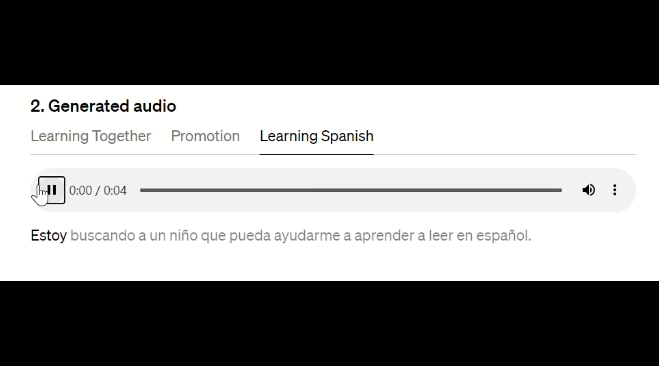 通过字幕学习西班牙语
通过字幕学习西班牙语
2.翻译场景-让声音无障碍的流向世界
制作的博客等声音内容,可以翻译成多种语音进行传播。值得一提的是,用于翻译时,语音引擎会保留原说话者的母语口音:用英语说话者的音频样本生成中文,就会产生带有英语口音的语音,主打一个真实。
3.为偏远地区提供服务
科技可以帮助我们与少数语音者进行无障碍沟通。例如案例中使用了语音引擎和 GPT-4 以每位工作人员的主要语言(包括斯瓦希里语或更非正式的语言)进行互动反馈。
生成的少数语种音频,51CTO技术栈,15秒
4.让失语者“发声”
语音引擎还设想为不会说话的人提供帮助。用户可以选择最能代表自己的语音,与他们进行交流。语音引擎还保证对多语种用户来说,每种口语都能保持一致的语音。让那些从未开口的人拥有一种音色,这就是科技的浪漫所在吧。
二、语音引擎的背后技术
1.模型训练——不能告知的训练数据
在接受外媒采访时,被问到模型训练数据的来源,OpenAI产品人员哈里斯变得非常谨慎。他表示,这些数据基于授权信息和公开信息。
由于训练数据通常涉及大量语音录音,且往往被视为商业秘密,关于训练数据和过程的具体细节往往保密。然而,这也导致了许多知识产权纠纷,例如纽约时报就曾对OpenAI提起诉讼。
随着技术的成熟,使用侵权素材训练模型的情况正在改善。OpenAI也已与国外Shutterstock、Axel Springer等内容提供商签订协议,并提供了阻止网络爬虫的选项,允许艺术家从其图像生成模型的数据集中撤回作品。
但现阶段,当科技高管们被问到这个问题,也许只能选择像OpenAI CTO Mira那样,做个“沉默的大多数”。
2.合成声音——无需微调的技术设计
令人惊讶的是,语音引擎并未进行微调。这在一定程度上得益于语音引擎独特的模型设计——通过扩散模型来即时生成语音。
哈里斯说:“我们采用少量音频样本和文本,生成与原始说话者相匹配的真实语音。” “请求完成后,所使用的音频将被删除。”
该模型通过分析语音数据和待朗读的文本,直接生成匹配的语音输出,无需为每个用户构建个性化模型。尽管语音克隆技术在业界已非新鲜事物,但OpenAI声称其方法能够提供更高质量的语音体验。
TechCrunch 称在OpenAI的营销文件(现在已经删除)中,Voice Engine 的定价为每百万字符(约 162,500 个单词)15 美元。这意味着大约 18 小时的音频,使得价格略高于每小时 1 美元。这确实比更受欢迎的竞争对手之一 ElevenLabs 的收费便宜——每月 100,000 个字符 11 美元。
但OpenAI的语音引擎目前还没有提供能调整语音细节的选项,如果初始声音是兴奋的或沮丧的,接下来合成的所有声音都只能保持这个情绪。
三、AI克隆技术是敌是友?
尽管OpenAI 让我们看到了语音克隆为“人类谋福利”的可行性,但随着 Deepfakes 的激增,相关技术是否能一直被负责任的使用或许还要打个问号。
此前,美国科技媒体The Verge曾报道过一次语音合成的诈骗案件。网络诈骗犯利用Deepfake仿制公司高管的语音,合成语音邮件发送至公司员工,对大型公司进行经济诈骗。国内也曾有过类似事件的报道。
当前的合成语音虽然逼真,但仍然有技术上的漏洞。美国安全咨询公司NISOS使用频谱工具对案件中Deepfake音频进行了分析,发现这段Deepfake语音的频谱图有峰值反复出现且音频不连贯。
相较于合成音频,真实人声的音高与音调都更为平滑。此外,放大合成音频的音量时,无法监测到该录音的背景噪音,这进一步表明这段音频是经过人为处理的。
然而,谁能保证随着技术的发展,Deepfake不会走向更深处呢?
当前,OpenAI尚并未开放语音引擎的访问权限。而是由红队的专家对其风险进行评估,并提出必要措施和减弱风险的策略,以阻止恶意使用。
哈里斯说,“我们不希望人们混淆合成声音和真实的人类声音。”
参考链接:
1.https://openai.com/blog/navigating-the-challenges-and-opportunities-of-synthetic-voices
2.https://techcrunch.com/2024/03/29/openai-custom-voice-engine-preview/
3.https://www.thepaper.cn/newsDetail_forward_8488082