
Cohere 教程:使用 Cohere 进行语义搜索

什么是语义搜索?
语义搜索是计算机按意思搜索的能力,超越了典型的关键字匹配搜索。语义搜索使用自然语言处理、人工智能和机器学习来理解用户的查询、查询的上下文和用户的意图。语义搜索着眼于单词之间的关系或单词的含义,以提供比传统关键字搜索更准确和相关的搜索结果。
语义搜索引擎有很多实际应用。例如,StackOverflow 的“相似问题”功能就是由这样的搜索引擎启用的。此外,它们还可用于为内部文档或记录构建私人搜索引擎。本文将向您展示如何构建一个基本的语义搜索引擎。本文介绍了使用问题存档进行嵌入、使用索引进行搜索以及基于嵌入的最近邻搜索和可视化。
让我们开始吧
对于此 Cohere AI 教程,我们将使用 Cohere 提供的示例数据。您可以在此处找到完整的笔记本代码
首先,我们将获取问题的存档,然后嵌入它们,最后使用索引和最近邻搜索进行搜索。最后,我们将基于嵌入可视化结果。要运行本教程,您需要有一个 Cohere 帐户。您可以在此处注册一个免费帐户。
让我们从安装必要的库开始。
!pip install cohere umap-learn altair annoy datasets tqdm然后创建一个新的笔记本或 Pythin 文件并导入必要的库。
import cohereimport numpy as npimport reimport pandas as pdfrom tqdm import tqdmfrom datasets import load_datasetimport umapimport altair as altfrom sklearn.metrics.pairwise import cosine_similarityfrom annoy import AnnoyIndeximport warningswarnings.filterwarnings('ignore')pd.set_option('display.max_colwidth', None)获取问题存档
接下来,我们将从 Cohere 获取问题存档。这个存档是 trecdataset,它是一个带有类别的问题集合。我们将使用库load_dataset中的函数来datasets加载数据集。
# Get datasetdataset = load_dataset("trec", split="train")# Import into a pandas dataframe, take only the first 1000 rowsdf = pd.DataFrame(dataset)[:1000]# Preview the data to ensure it has loaded correctlydf.head(10)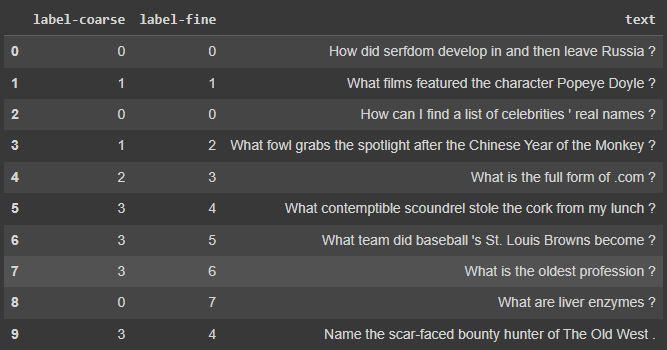
嵌入问题档案
现在我们可以使用 Cohere 嵌入问题。我们将使用embedCohere 库中的函数来嵌入问题。生成一千个这种长度的嵌入应该只需要几秒钟。
# Paste your API key here. Remember to not share publiclyapi_key = ''# Create and retrieve a Cohere API key from dashboard.cohere.ai/welcome/registerco = cohere.Client(api_key)# Get the embeddingsembeds = co.embed(texts=list(df['text']), model='large', truncate='LEFT').embeddings现在我们可以建立索引并搜索最近的邻居。我们将使用库AnnoyIndex中的函数。在annoy给定集合中找到最接近(或最相似)给定点的点的优化问题称为最近邻搜索。
# Create the search index, pass the size of embeddingsearch_index = AnnoyIndex(embeds.shape[1], 'angular')# Add all the vectors to the search indexfor i in range(len(embeds)): search_index.add_item(i, embeds[i])search_index.build(10) # 10 treessearch_index.save('test.ann')从数据集中查找示例的邻居
我们可以使用我们建立的索引来找到现有问题和我们嵌入的新问题的最近邻居。如果我们只对测量数据集中问题之间的相似性感兴趣(没有外部查询),一种简单的方法是计算我们拥有的每对嵌入之间的相似性。
# Choose an example (we'll retrieve others similar to it)example_id = 92# Retrieve nearest neighborssimilar_item_ids = search_index.get_nns_by_item(example_id,10, include_distances=True)# Format and print the text and distancesresults = pd.DataFrame(data={'texts': df.iloc[similar_item_ids[0]]['text'], 'distance': similar_item_ids[1]}).drop(example_id)print(f"Question:'{df.iloc[example_id]['text']}'
Nearest neighbors:")results # only in notebooks, use print(results) in scripts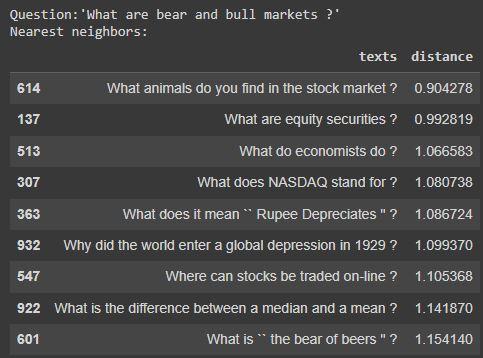
查找用户查询的邻居
我们可以使用诸如嵌入之类的技术来查找用户查询的最近邻居。通过嵌入查询,我们可以测量它与数据集中项目的相似性并识别最近的邻居。
可视化
#@title Plot the archive {display-mode: "form"}# UMAP reduces the dimensions from 1024 to 2 dimensions that we can plotreducer = umap.UMAP(n_neighbors=20) umap_embeds = reducer.fit_transform(embeds)# Prepare the data to plot and interactive visualization# using Altairdf_explore = pd.DataFrame(data={'text': df['text']})df_explore['x'] = umap_embeds[:,0]df_explore['y'] = umap_embeds[:,1]# Plotchart = alt.Chart(df_explore).mark_circle(size=60).encode( x=#'x', alt.X('x', scale=alt.Scale(zero=False) ), y= alt.Y('y', scale=alt.Scale(zero=False) ), tooltip=['text']).properties( width=700, height=400)chart.interactive()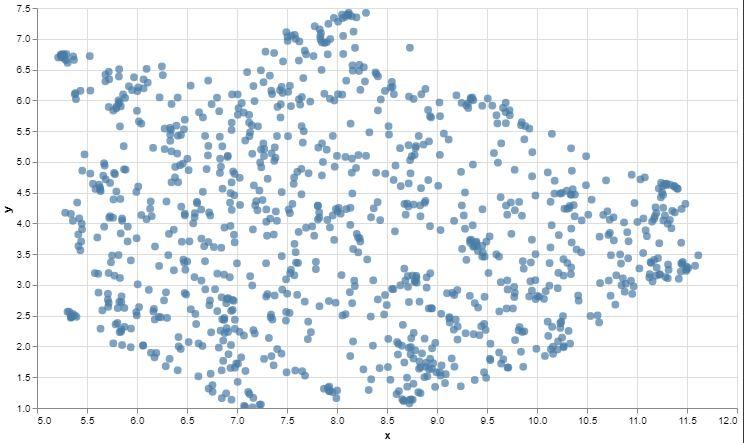
这使我们结束了这个关于使用句子嵌入进行语义搜索的介绍性指南。展望未来,在构建搜索产品时,还有其他因素需要考虑(例如处理冗长的文本或为特定目的优化嵌入的培训)。随意探索和试验其他数据。
您可以在活动页面上找到即将举行的黑客马拉松和活动。
确定您周围的问题并构建 cohere 应用程序来解决它。
谢谢你!如果您喜欢本教程,您可以在我们的教程页面上找到更多信息并继续阅读 – AI未来百科 ; 探索AI的边界与未来! 懂您的AI未来站