
AI艺术提示指南:如何用自己的数据集重新训练YOLOv7模型?

在本教程结束时,您将能够使用您的自定义数据集重新训练 YOLOv7 模型,并对您自己的图像进行简单的预测。
🚀 开始
📚 上传数据集
您需要做的第一件事是将数据集上传到您的 Google 云端硬盘。我将使用来自 Roboflow 网站的 BCCD 数据集,但你可以使用任何你想要的数据,但请记住它必须是适合 YOLO 的格式。本文将告诉您标签在 YOLO 格式中应该是什么样子。
🔑 重要提示。请记住在数据的配置文件中包含有关数据文件夹路径的信息。在我的例子中,文件结构如下所示(您可以在左侧栏中的 📁 图标下查看)。
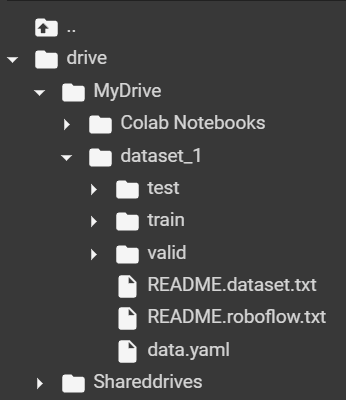
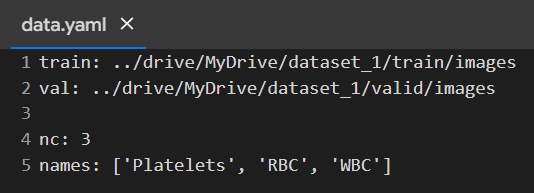
配置文件 (data.yaml) 如下所示:
📓 创建笔记本
然后让我们转到 Google Colab 并创建一个新笔记本。当然,为了加快训练过程,我们会将运行时类型更改为 GPU。为此,请转到“运行时”选项卡,然后选择“更改运行时类型”,然后在“硬件加速器”选项中选择“GPU”并保存。
准备好环境后,我们就可以开始编码了!
🤖 编码
💽 连接 Google Drive 并准备模型
因此,让我们从连接 Google Drive 开始:
from google.colab import drivedrive.mount('/content/drive')然后我们必须克隆 YOLOv7 存储库
!git clone https://github.com/WongKinYiu/yolov7.git让我们去克隆目录
cd yolov7并安装依赖项
!pip install -r requirements.txt现在我将下载一个版本的 YOLOv7 模型。我将使用 YOLOv7-tiny 模型,但你可以使用任何你想要的模型。在这里您可以找到型号列表
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-tiny.pt🏃🤖 训练模型!
下载模型后,我们就可以开始训练了!您可以随意调整以下参数。我会用这些。请记住,如果更改模型类型(或任何其他内容,如数据路径),则必须在本教程后面的部分连续更改其名称。
!python train.py --workers 8 --device 0 --batch-size 32 --data ../drive/MyDrive/dataset_1/data.yaml --img 416 416 --cfg cfg/training/yolov7-tiny.yaml --weights 'yolov7-tiny.pt' --name yolov7-tiny --hyp data/hyp.scratch.custom.yaml --epochs 40在这一步之后,我们可以尝试进行测试预测。我将从有效集中给你一张图片。您可以尝试使用任何您想要的图像。只需更改参数路径即可--source。
!python detect.py --weight runs/train/yolov7-tiny/weights/best.pt --conf 0.35 --img-size 416 --source ../drive/MyDrive/dataset_1/valid/images/BloodImage_00000_jpg.rf.67c4a4312251eaa52b6ea2f2edf4855b.jpg现在让我们运行所有单元并等待结果!训练过程可能需要很长时间,具体取决于您提供的参数以及数据的数量和大小。
该模型将实时打印指标,因此您可以跟踪模型的性能。还可以连接实验跟踪工具 – W&B – 它将返回模型的整个训练报告。
并且有测试检测的结果。让我们亲眼看看,经过短短 18 分钟的培训,您是否满意!

✨ 结论
YOLOv7 是一个很好的模型,可以提高我们的能力,而且易于使用,性能也很好。创建使用此模型并迅速取得成功的应用程序并不困难。我期待着推动我们发展的下一个模型!
我希望你也能从 YOLOv7 中获得乐趣。
请继续关注未来的教程!
谢谢你!– AI未来百科 ; 探索AI的边界与未来! 懂您的AI未来站